How BSP Technologies® Stabilised a Global Fitness App: From Failing Modules to a 90% CPU Reduction in 48 Hours
When fast-growing digital products begin to scale, issues that look small on the surface often reveal deeper architectural cracks underneath.
This is exactly what happened when a global fitness brand serving 5,000+ recurring customers across multiple countries reached out to BSP Technologies®.
The product had strong potential:
A sleek mobile app
A supporting web admin panel
A rapidly growing subscriber base
Global expansion already in motion
But the internal systems were unreliable, inconsistent, and collapsing under hidden load.
This is the story of how our engineering team restored stability, rebuilt trust, and transformed a struggling system into a high-performance, scalable platform within weeks.
1. The Problems the Client Faced
Before approaching bsp technologies®, the brand had been working with a previous freelance team. Over time, the product started showing severe issues:
- Critical modules were failing frequently: Leaderboard, session tracking, metrics, rewards, and daily activity sync. Everything was unstable.
- Subscription tracking was inaccurate: With thousands of recurring customers, even minor misalignment caused revenue confusion.
- Onboarding broke depending on the sales channel:Each partner or funnel sent different data formats → inconsistent user journeys.
- Session recordings were still manually entered:Operational drag, human error, and no validation.
- Wearable + health metric sync was broken
Step count didn’t update
Watch/Health Connect data failed
Digital scale readings never reached the server
This directly affected leaderboard accuracy, user motivation, milestone rewards, and diet planning the heart of the product.
2. Our First Step: Diagnose, Don’t Patch
Rather than rushing into fixes, we deployed a cross-functional team to conduct a deep technical audit:
Code review
Infrastructure review
Query analysis
Cron job inspection
End-to-end subscription validation
Device sync flow mapping
App–server communication behaviour
Within the first month, we had a complete map of root causes.
3. Phase 1: Fixing the Core Functional Failures
Our team rolled out the first production update covering:
Correct step and health metric sync
Accurate subscription state logic
Clean onboarding flow
Stable leaderboard and milestone tracking
Fixed diet plan metric dependency
Repaired workout session behaviour
To prevent a single user from reporting broken rewards or inaccurate progress, we proactively synced:
✔ All users’ step + watch metrics for the last 30 days
This eliminated historic discrepancies and prevented fresh complaints from day one.
This extra step earned immediate trust from the client.
4. Phase 2: The Unexpected The Server Went Down
The day after the update, the client called:
“The application is down.”
We requested AWS access (still in transition at the time), logged in, and saw this:
CPU usage: locked between 45% and 60% all day even when no users were active.
This wasn’t a normal load.
This was a system slowly collapsing.
Below is the actual CPU graph before the fixes:
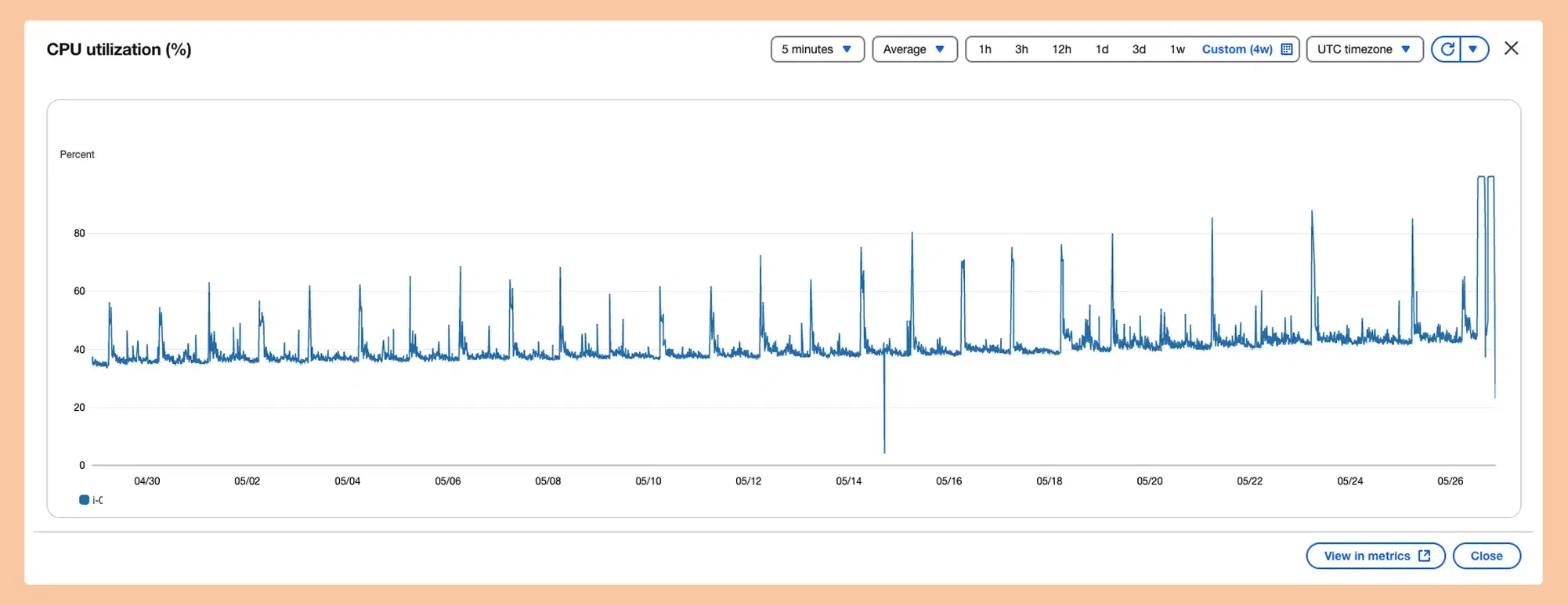
The pattern indicated:
Internal processes → not user traffic
Identical energy spikes → timed tasks
Repetitive load → something running every minute
And then we found it.
The Root Cause: 25 Cron Jobs Running Every Minute
The previous team had built:
25 different cron jobs
All executing every 60 seconds
Running heavy, unoptimised queries
Sending notifications across time zones
With no batching & no checks
Even when workloads did not exist
It was a textbook example of how poor task scheduling destroys server health.
We prepared a detailed issue document and asked for three days to repair the architecture. The client agreed immediately.
5. Phase 3: Fixing the Foundation The Right Way
In just 48 hours, our team:
Rewrote every major cron job
Eliminated redundant schedules
Added indexing to heavy queries
Introduced queue-based task handling
Grouped notifications by time zone
Applied conditional logic
Removed dead code paths
Split load where required
Cleaned the scheduling architecture
After deployment, the difference was night and day.
6. CPU usage dropped from 45–60% → stable 5%
Here is the after-optimisation CPU graph:
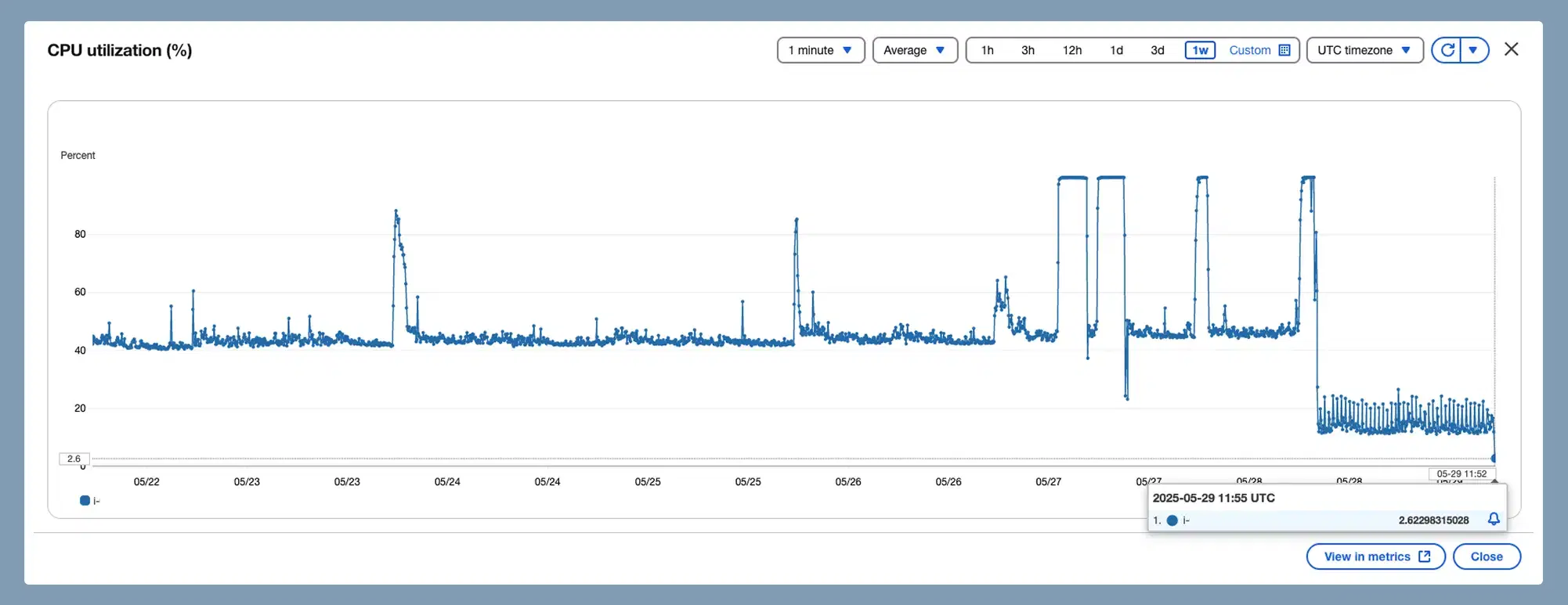
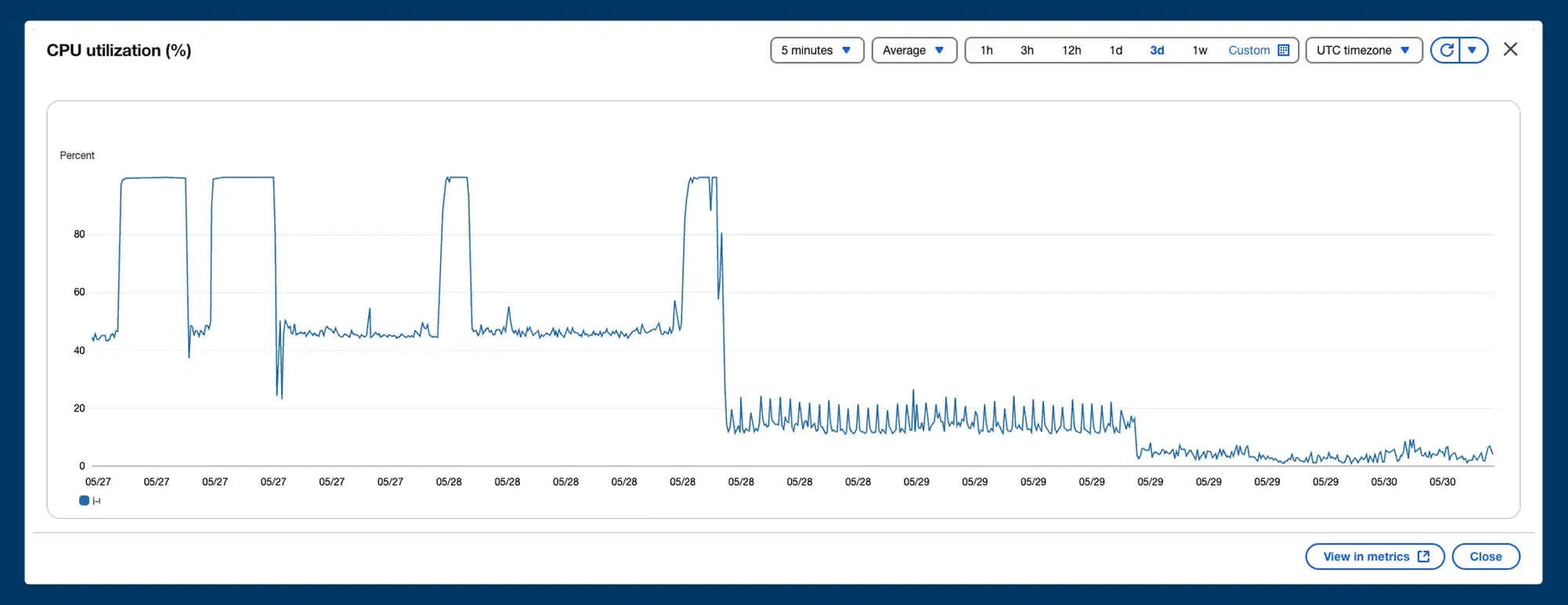
The system became:
Faster
Predictable
Cost-efficient
Scalable
Stable under load
Ready for global expansion
7. The Outcome
Within weeks, the client moved from instability and user complaints to a performance-driven, predictable system.
8. What we achieved:
Fixed all functional issues in a single release
Restored data accuracy for all users
Stabilised the system for global scaling
Reduced CPU usage by up to 90%
Eliminated hidden architectural risks
Delivered fast without excuses
Achieved all improvements without downtime
Provided constant communication throughout
9. What This Project Proves
At BSP Technologies®, we don’t treat engineering as task execution.We treat it as ownership.
This project reflects our core values:
No blame shifting
No delays
No excuses
Root cause before patching
Clear communication
Fast execution
Long-term thinking
Most importantly we protected the client’s business, not just their code.
10. Final Thoughts for SaaS Founders & CTOs
If your product is growing but stability isn’t keeping up, you don’t need more developers you need the right architectural decisions.
This project is a perfect example of how:
A few hidden issues can sink user trust
Good engineering can turn a product around
Proactive steps can prevent future failures
A stable system accelerates growth
At BSP Technologies®, we specialise in rescuing, restructuring, and scaling digital products across industries.
If your system is facing performance issues, operational bottlenecks, or scalability challenges